
What does the growth of the “digital humanities”—a host of technologically aided approaches ranging from algorithmic analysis of data to digital mapping to the analysis of technology itself—mean for the field? Steven Rings from Music and David Schloen from Near Eastern Languages and Civilizations offer their opinions.
---
Steven Rings is an associate professor in Music.
 New technologies are an old story in the humanities. Indeed, the history of the humanities is arguably untellable without a parallel history of the once-new technologies that provided its conditions of possibility. To pluck the lowest-hanging fruit first, there is of course Gutenberg’s printing press, conveniently situated at the historical threshold of what we now call Renaissance Humanism. But the diverse scribal traditions that preceded it were no less technological. Consider the ancient Egyptian scribe’s palette, which predates Gutenberg’s press by at least 1,000 years: to call one a technology but to exclude the other is to draw an arbitrary line. Among other things, both technologies performed a crucial mnemonic role, “remembering” texts for the scholar and freeing up cognitive resources for interpretation: as texts are duplicated, by hand or by press, they become objects to be fastidiously scrutinized, compared, and interpreted—behaviors central to the humanistic habitus. The advent of music notation, dating back to monastic scribal traditions and given a boost by Italian printing presses around 1500, performed a similar role for thought about music. Indeed, musicology is all but inconceivable without the technology of music notation. But why stop here? The many recent scholarly studies of hominid origins remind us again and again that human expressive culture has always been inextricably bound up with tool use and the technological: think of cave paintings, bone flutes.
New technologies are an old story in the humanities. Indeed, the history of the humanities is arguably untellable without a parallel history of the once-new technologies that provided its conditions of possibility. To pluck the lowest-hanging fruit first, there is of course Gutenberg’s printing press, conveniently situated at the historical threshold of what we now call Renaissance Humanism. But the diverse scribal traditions that preceded it were no less technological. Consider the ancient Egyptian scribe’s palette, which predates Gutenberg’s press by at least 1,000 years: to call one a technology but to exclude the other is to draw an arbitrary line. Among other things, both technologies performed a crucial mnemonic role, “remembering” texts for the scholar and freeing up cognitive resources for interpretation: as texts are duplicated, by hand or by press, they become objects to be fastidiously scrutinized, compared, and interpreted—behaviors central to the humanistic habitus. The advent of music notation, dating back to monastic scribal traditions and given a boost by Italian printing presses around 1500, performed a similar role for thought about music. Indeed, musicology is all but inconceivable without the technology of music notation. But why stop here? The many recent scholarly studies of hominid origins remind us again and again that human expressive culture has always been inextricably bound up with tool use and the technological: think of cave paintings, bone flutes.
Racing ahead from Gutenberg, the examples become ever more vivid, and more obvious: typewriter, camera, phonograph, film, computer, internet, MP3, Google. In 2015 those of us who spend our days in humanistic pursuits move fluidly and effortlessly among technologies, our laptops switching applications with ease. Google alone has become so ready-to-hand that it can even recede from our awareness, Heidegger style: we perform a search almost without realizing we have done so. (Heidegger, “The Question Concerning Technology,” 1954.)
So where does this leave us with respect to the host of approaches often arrayed under the banner of the “digital humanities”: data mining, machine learning, digital mapping, network visualization, and so on. To put the question simply, is this merely a difference in degree—more technologies, and more powerful—or have we crossed some sort of qualitative Rubicon, a difference in kind that would transform the humanities as we know it? My opening gambit of course suggests the former, but I don’t want to seem overly sanguine, or undialectical, about our present moment. The institutional, financial, and political challenges that the humanities face are very real, and I do not feel that the digital humanities (or DH, as they are often known) are merely a value-neutral adrenaline shot for the discipline, turning our technological commitments “up to 11” but leaving our intellectual and ideological ones untouched.
Nevertheless, I don’t share the worry that the advent of DH will cause the humanities to be subsumed into the sciences or—more nefariously—to become somehow lost in the technology itself, nuanced discourses of value and meaning dissolving in a vast sea of 1s and 0s. On the contrary, in my experience, new technologies have a way of bringing into focus precisely those humanistic surpluses that elude quantification: questions of significance, identity, phenomenology, affect, and so on. To clarify, I’ll close with two examples from my own work. The first is a classic instance of “distant reading”—the kind that big data makes possible, and that critics of DH often bemoan. This is a graph of all of Bob Dylan’s performances of the song “It’s Alright, Ma (I’m Only Bleeding)” from 1964 until 2013. Gray bars indicate the number of concerts in a given year; black bars show the number of performances of the song in question. One detail interested me: during two periods of heavy touring, the song fell out of set lists. Why? Without this particular data visualization, I never would have asked the question. But with it, an answer immediately suggested itself: these were the Clinton and early Obama years. And this is a song that includes a famous, cheer-inducing line about the president of the United States standing naked. Dylan’s own politics are somewhat opaque these days, but he knows his left-leaning audience: that line will get a much bigger roar during a Bush administration than a Clinton one. How striking, then, to notice that he brought the song back in the wake of the Monica Lewinsky scandal in 1999 and the botched rollout of the Affordable Care Act in 2013. Standing naked, indeed. Thousands of pages have been written on Dylan’s politics. This bit of "big data" visualization provides a new perspective on the confluence of showbiz decision making, crowd affect, and the aesthetic affordances of the political: one that calls for more careful humanistic analysis, not less.
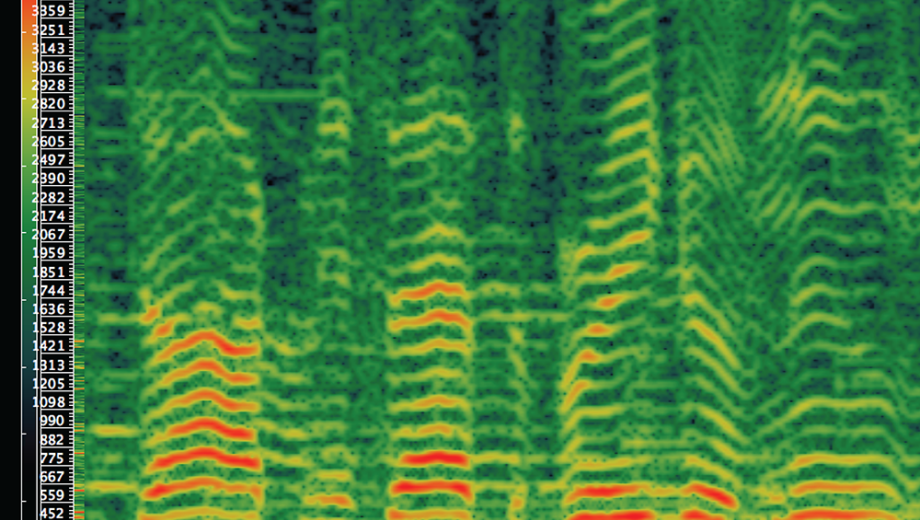
My second example zooms in for some extremely close reading—or better, close listening. Here is a spectrogram of Dylan’s studio performance of the same song’s first line in January 1965. Spectrograms can be used for many things; here I employ one to explore what music analysts call microtiming. Arrows beneath the spectrogram show the beats marked by Dylan’s guitar downstrokes; as the other annotations show, Dylan consistently begins singing before each downstroke, anticipating the beat by around 150 milliseconds. But who cares? Why does this matter? The spectrogram can’t tell us. The observation led me to notice Dylan’s performances of the song in later eras, as on the 1974 tour with The Band, when his voice and guitar were in precise alignment. In those eras, Dylan explicitly indexes white vernacular traditions—especially country—as opposed to the black rural traditions he mimics on the studio recording. This granular visualization thus reveals one way in which Dylan’s body of work encodes racial difference, via a performative detail that is extremely easy to miss without spectrographic assistance. And with this, vexed questions of ideology, embodiment, performance, and race come flooding back. The ghost in the machine, as it turns out, is all too human.
---
David Schloen is an associate professor in Near Eastern Languages and Civilizations.
 How do computers fit into humanities research? This topic is getting a lot of attention with the proliferation of new centers, journals, and even professorships of digital humanities. Here at the University of Chicago we have a new standing committee to facilitate work in this area. We have reorganized our technical support structure and have launched a new course sequence entitled Introduction to Digital Humanities. We have adopted a broad definition of digital humanities as being concerned with the following four things: First, there is the digital representation of knowledge. This includes digital encoding of texts, images, and sound—and, more generally, the data structures and formal ontologies used to represent the entities, concepts, and relationships of interest to scholars.
How do computers fit into humanities research? This topic is getting a lot of attention with the proliferation of new centers, journals, and even professorships of digital humanities. Here at the University of Chicago we have a new standing committee to facilitate work in this area. We have reorganized our technical support structure and have launched a new course sequence entitled Introduction to Digital Humanities. We have adopted a broad definition of digital humanities as being concerned with the following four things: First, there is the digital representation of knowledge. This includes digital encoding of texts, images, and sound—and, more generally, the data structures and formal ontologies used to represent the entities, concepts, and relationships of interest to scholars.
Second, there is the automated analysis of cultural and historical information. This includes algorithmic methods for tasks ranging from simply searching a database to detecting patterns in the corpora we study via spatial analysis, social network analysis, and machine learning.
The third area of digital humanities involves the presentation of information for pedagogical instruction, for the visualization of research results, and for creative expression—for example, via algorithmically generated visual art and music.
The fourth area involves the social and institutional contexts and effects of digital technology. This entails critical reflection about software as a cultural product that has its own history and biases, depending on when and where it was created, and by whom.
This last topic—the contexts and effects of digital technology—plays to the strengths of humanities researchers. By investigating how and why currently dominant modes of digital knowledge representation have arisen, we can put them in proper perspective, seeing them not as universal and logically necessary, but as historically contingent creations that reflect particular concerns. Not surprisingly, most software reflects the interests of large hierarchical organizations, be they commercial or governmental, which have paid for the creation of the software and want it to suit their purposes.
A good example is the digital representation of texts by means of long strings of character codes interspersed with special embedded codes called “markup.” Markup specifies formatting, style, font, and more—for example, “<italic>.” This simple method of text representation emerged from the business world and is well nigh universal. It was borrowed by humanities researchers and has become deeply rooted in digital humanities. But it is not the only way to represent texts digitally and is far from being the best way to represent complex literary or historical texts that can be read in many different ways. This method of text representation was not designed with scholars in mind. It makes it difficult to represent multiple readings of the same text in a way that is conducive to scholarly study.
So, from the point of view of software design, the historical study of computing systems as cultural products is not just an ornamental frill of no practical value. It brings to the surface assumptions about what is deemed to be worth knowing and how one ought to manipulate knowledge. It reveals the extent to which the conceptual models that underlie particular data formats and algorithms are not universal but are dictated by particular needs and assumptions. For example, in the corporate world, it is assumed that there is an anonymous semantic authority that will impose a standardized taxonomy or ontology on the members of the organization (using the term “ontology” here to refer to a conceptual model of entities and their relationships).
The challenge for us is to design software suitable for academic research, respecting the way that knowledge is created, organized, and attributed to named individuals in the academic setting. This focuses attention on what is common across the humanities with respect to how knowledge is structured and manipulated, and what the humanities share with other academic disciplines. I am thinking here of a common computational problem that is painfully evident in the humanities but is also found in the sciences, especially in biology—namely, the problem of “ontological heterogeneity” that arises when divergent taxonomies and conceptual models are used by different people to describe the same things. The typical attitude in the business world is to reduce or eliminate ontological heterogeneity by imposing standardized taxonomies, at least within a given organization. This is possible because there is a single semantic authority that can legislate standards. Too often in humanities computing there have been attempts to do the same, as if a standardized mode of description of literary texts or archaeological artifacts were necessary for computational work.
But, apart from the fact that there is no single semantic authority we must all obey, many scholars would agree that ontological heterogeneity is not a vice to be eliminated but is actually a defining virtue of our mode of research. Scholars do not assume that there is a single, univocal language for describing the world. Indeed, we reward people who come up with new ways of seeing familiar objects of study. There is a high degree of ontological heterogeneity in many fields of the humanities—I know this is true in archaeology, my own discipline. This is not simply the result of egotism but reflects different research questions and paradigms of interpretation. Thus, we should not be forced to conform to an alien ontology and sacrifice semantic authority just because widely used software was designed in a different institutional setting under the assumption that semantic standards would somehow be imposed. There is nothing inherent in digital computing that requires such standards. We simply need software that has been designed with our interests in mind and conforms to our research practices.
In my own work in digital humanities, I have been developing methods for representing the idiosyncratic conceptual distinctions made by individual scholars concerning their objects of study. Ontological diversity, observational uncertainty, and interpretive disagreement can be explicitly represented within a larger common framework in which researchers may analyze and compare many different observations, interpretations, and terminologies to inform their own judgments. Here is a way in which the humanities are not simply dependent on computing methods developed elsewhere but can bring something important to software engineering itself—namely, an awareness of the historicity of formal knowledge representations and a vision for what they should look like in a multivocal context, under conditions of semantic autonomy.
A final point I would make here is that digital humanities need not entail the abandonment of traditional scholarly practices. It is sometimes suggested that the adoption of digital methods will radically transform and reconfigure our disciplines—for example, as literary scholars learn about statistical machine learning and as historians use social network analysis to model social groups and institutions. I am not so sure about that. I think the type of formalization one adopts, and thus the relevant kind of computation, if any, will depend on the questions one is asking. There are scholarly questions and interpretive paradigms for which digital methods may seem overly reductive and thus be rejected in principle.
And within the broad range of what is included under the rubric of digital humanities, we may have qualms about the automated analysis of large textual corpora to detect patterns across thousands of texts—what has come to be called “distant reading” as opposed to “close reading,” to use a distinction made popular by Franco Moretti. The philosophical assumptions about texts and linguistic discourse that lie behind distant reading are not shared by all. However, the automated analysis of large corpora in the style of Moretti is only one aspect of digital humanities. Equally important is the step we must take before we get to algorithmic analysis, namely, the initial representation of cultural knowledge in digital form. As I have said, the challenge is to design software that captures the conceptual distinctions and relationships of interest to scholars and to do so in a way that is faithful to our own research practices. In so doing, we are not abandoning traditional practices but drawing attention to them and rehabilitating them, as Jerome McGann does when he argues for a revival of nineteenth-century philology as the paradigm of humanities research enabled by the digital web of knowledge. Perhaps the digital tools are taking us “back to the future”—realizing in a new way an old vision of Wissenschaft.
This text is edited and condensed from IDEAS remarks given at “Humanities Research: The Future of an Idea,” a program in honor of the Franke Institute for the Humanities’ 25th anniversary in November 2015.